Database schema¶
A CReM fragment database is a single SQLite file. CReM reads two formats:
- v1 — the current, deduplicated schema written by
cremdb_create. Identified byPRAGMA user_version = 1. - v0 — the legacy single-table-per-radius layout written by the
pipeline. Identified by
PRAGMA user_version = 0(the default).
Every generation function works with both formats. Older v0 databases can be converted into v1.
To check a database's format:
sqlite3 fragments.db "PRAGMA user_version;" # 1 = v1, 0 = v0v1 schema (current)¶
v1 normalizes the data into shared tables so that each environment, fragment, and H-capped fragment is stored only once, then references them from per-radius mapping tables.
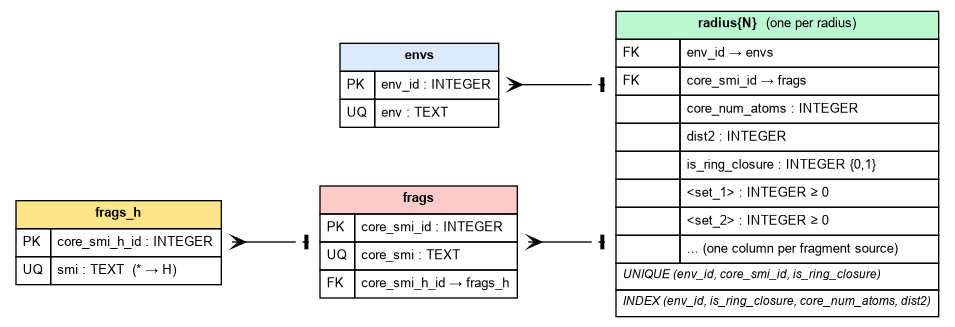
envs — context environments¶
CREATE TABLE envs(
env_id INTEGER PRIMARY KEY AUTOINCREMENT,
env TEXT NOT NULL UNIQUE
);One row per distinct canonical context (environment) SMILES.
frags_h — H-collapsed fragments¶
CREATE TABLE frags_h(
core_smi_h_id INTEGER PRIMARY KEY AUTOINCREMENT,
smi TEXT NOT NULL UNIQUE
);Each core fragment with every attachment point [*] replaced by hydrogen.
This groups together cores that differ only in where they attach. Deduplicated
by this H-collapsed SMILES.
frags — fragments (cores)¶
CREATE TABLE frags(
core_smi_id INTEGER PRIMARY KEY AUTOINCREMENT,
core_smi TEXT NOT NULL UNIQUE,
core_smi_h_id INTEGER NOT NULL,
FOREIGN KEY (core_smi_h_id) REFERENCES frags_h(core_smi_h_id)
);One row per distinct core SMILES (with attachment points). Optional
property columns (mw, logp, …) are added to this table on
demand and are therefore not present in a freshly built database.
radiusN — context-to-fragment mapping (one per radius)¶
CREATE TABLE radius3(
env_id INTEGER NOT NULL,
core_smi_id INTEGER NOT NULL,
core_num_atoms INTEGER NOT NULL,
dist2 INTEGER NOT NULL,
is_ring_closure INTEGER NOT NULL DEFAULT 0,
-- one INTEGER frequency column per fragment set, e.g.:
chembl INTEGER NOT NULL DEFAULT 0,
FOREIGN KEY (env_id) REFERENCES envs(env_id),
FOREIGN KEY (core_smi_id) REFERENCES frags(core_smi_id),
UNIQUE (env_id, core_smi_id, is_ring_closure)
);Each row links a context (env_id) to a core (core_smi_id) observed in that
context at this radius. Columns:
| Column | Meaning |
|---|---|
core_num_atoms |
heavy-atom count of the core (denormalized here so size filters need no join) |
dist2 |
topological distance between the two attachment points for 2-attachment cores; 0 otherwise |
is_ring_closure |
0 for acyclic-cut fragments, 1 for ring-cut (ring-closure) fragments — see frag modes |
| set columns | one per fragment set; the value is the occurrence count in that set |
Because is_ring_closure is part of the UNIQUE key, the same
(env, core) pair can store an acyclic row and a ring-closure row
independently, each with its own per-set counts.
Indices¶
The UNIQUE constraints already create autoindices on envs(env),
frags(core_smi), frags_h(smi), and
radiusN(env_id, core_smi_id, is_ring_closure). In addition, exactly one
covering index per radius supports the hot query path:
CREATE INDEX idx_radius3_lookup
ON radius3(env_id, is_ring_closure, core_num_atoms, dist2);How a query uses it¶
At generation time CReM resolves the molecule's context to an env_id, then
selects matching cores from radiusN filtered by core_num_atoms (size),
dist2 (linker/ring geometry), is_ring_closure (provenance), and the chosen
set column against min_freq. The selected core_smi_ids are joined to frags
to obtain the replacement SMILES.
v0 schema (legacy)¶
v0 stores everything denormalized in one table per radius:
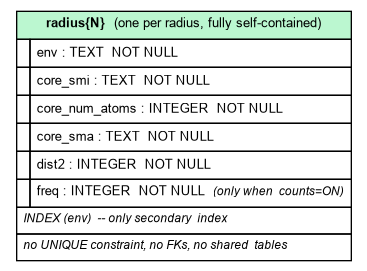
CREATE TABLE radius3(
env TEXT,
core_smi TEXT,
core_num_atoms INTEGER,
core_sma TEXT, -- core reaction SMARTS
dist2 INTEGER,
freq INTEGER -- present only when built with occurrence counts
);
CREATE INDEX radius3_env_idx ON radius3(env);The freq column exists when the database was built from sort | uniq -c
counts (see the v0 pipeline). v0 has no notion of multiple
fragment sets or ring-closure provenance; set_names is ignored for v0
databases.
When filtering fragments with extra **kwargs (property filters), v0 reads the
named columns from the radiusN tables, whereas v1 reads them from frags /
frags_h.